


Gráf adatbázis alapok
Őszintén bevallom, nem nagyon volt még szerencsém Graph Database-hez korábban. Egy nemzetközi konferencián járva egy kis közvéleménykutatást tartva is azt találtam, hogy még eléggé gyermekcipőben van a dolog, pédául statisztikai adatok feldolgozása során (a meginterjúvolt jelenlévők körében legalábbis) senki sem használ jelenleg ilyen adatbázist. Ez persze nem azt jelenti, hogy más területeken ne lehetne létjogosultsága, de azért az látszik, hogy a technológia még nem teljesen kiforrott. A relációs adatbázisok több évtizede velünk vannak, szemben velük a Graph Database csak a 2000-es évektől kezdett el szélesebb(?) körben is elterjedni.
Mi is az a Graph Database?
A NoSQL adattárolási módszerhez soroljuk, azzal szemben azonban (amely az adatokat implicit módon köti össze), itt az adatok közötti kapcsolat alapvető fontosságú. Egyszerűen megfogalmazva gráf adatbázis esetén maga az adatok közötti kapcsolatok egyenlő fontosságúak magukkal az adatokkal, szemben a relációs adatbázisokkal, ahol a kapcsolatot "mindössze" JOIN-okkal tudjuk megvalósítani. A fő lényege pont ez, hogy egy olyan adatbázisnál, ahol megannyi adattáblával dolgozunk megannyi adattal, egy bizonyos komlexitáson túl a relációs adatbázisban összeállított lekérdezések is rendkívül komplexekké válhatnak. Erre próbál megoldást adni a gráf adatbázis, amelynél a kapcsolatok maguk döntő fontosságúak már az adatbázis felépítése során, ezzel az abból történő lekérdezések hatékonyságát javítva. Főbb működési eleve szerint csak azokat a kapcsolatokat térképezi fel és adja vissza, amelyek megfelelnek a keresési feltételeknek, minden mást figyelmen kívül hagy. Ezáltal nagy méretű adatbázisok esetén jóval hatékonyabban és gyorsabban tud dolgozni, mint relációs társa.
Főbb elemei az alábbiak:
- nodes: ha mondjuk a Facebook-ot tekintjük példaként, akkor a node-ok maguk felhasználók, mindegyik adott attribútummal (név, kor, stb.), amelyeket properties-nek nevezünk. Relációs adatbázis esetén ezt megfeleltethetjük egy tábla rekordjának.
- edges - lines - relationships: ez maga az összekötővonal, ami az egyes node-okat összekapcsolja, a közöttük meglévő kapcsolat attribútumával (a Facebook hasonlat esetén ez lehet mondjuk a kapcsolat típusa a két felhasználó között - barát/rokon/stb).
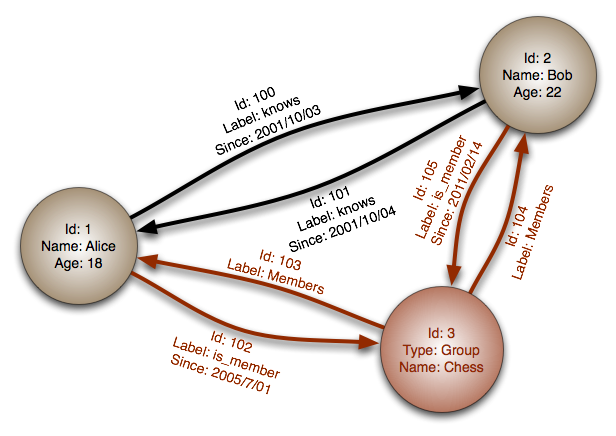
Az eddigiek alapján elsősorban ott lehet létjogosultsága, ahol az adatok nagy mértékben kapcsolódnak egymáshoz, elsősorban many-to-many kapcsolattal, lásd social network esete. De használják még üzleti területen is több helyen (fraud detection, vagy risk management területén).
Főbb adatbázis típusok:
Többféle adatbázist használnak nagyobb körben, viszont ezzel együtt azt is meg kell említeni, hogy jelenleg nincsen olyan egységesen kiforrott nyelv, mint az SQL esetében van, azaz ahány adatbázis, annyi nyelvezet. Pár ilyen adatbázis:
- Neo4j
- Microsoft Azure Cosmos DB
- JanusGraph
Elméleti alapként egyelőre ennyit, de fogunk még foglalkozni itt ezekkel az adatbázisokkal a későbbiekben. Mindenesetre fontos megjegyeznem, hogy jelenleg még igen alacson az olyan szinten hozzáértő szakértők száma, akik nyugodt szívvel tudnának dönteni arról, hogy egy adott felhasználási terület esetében melyik adatbázis típust is lenne érdemes használni. Maradjunk a relációs adatbázisnál? Jó lesz a NoSQL is? Induljunk el a Graph Database felé? Mivel a technológia viszonylag új, szükség van a döntéshozók ismeretének bővítésére, és arra, hogy az ilyen kaliberű kérdések kapcsán minden érintettet bevonjunk a döntéshozatalba.
